
The advent of Artificial Intelligence, especially generative AI and autonomous agents, marks a profound transformation in technology. Yet, this unprecedented power comes with complex, new risks: data poisoning, prompt injection, model evasion, and sensitive data disclosure. Deploying AI responsibly and securely is no longer optional; it’s a prerequisite for trust, regulatory compliance, and unlocking AI’s full potential.
Google, with decades of experience securing global infrastructure and leading AI research, has formalized its approach into the Secure AI Framework (SAIF). Introduced in 2023, SAIF is Google’s externalization of its own battle-tested internal framework for securing AI systems throughout their entire lifecycles. It’s not just a set of guidelines; it’s a comprehensive, lifecycle-aware roadmap designed to make AI models and applications secure by design.
This is the first in a three-part series exploring SAIF. Here, we’ll dive into SAIF’s core concepts, its foundational principles, and why adopting such a framework is critical for any organization building or deploying AI.
What to Remember
- SAIF is Foundational: It’s Google’s holistic, lifecycle-aware framework for securing AI systems from data to application.
- Beyond Traditional Security: AI agents introduce unique attack surfaces (memory, autonomous planning, tool use) that traditional security measures can’t fully address.
- Hybrid Defense-in-Depth: SAIF advocates combining deterministic security controls with dynamic, AI-reasoning based defenses.
- Three Core Agent Principles: Human control, limited powers, and observability are non-negotiable for agent security.
- Layered Controls: SAIF organizes controls across Data, Infrastructure, Model, Application, Assurance, and Governance layers to address a wide range of AI-specific risks.
1. What is the Google Secure AI Framework (SAIF)?
At its essence, SAIF is a conceptual framework designed for practitioners security professionals, developers, and data scientists to ensure AI models and applications are secure by design. It’s technology-agnostic, meaning its principles apply whether you’re using Google’s Gemini, open-source LLMs, or proprietary models.
SAIF’s Core Purpose:
- Identify Risks: Pinpoint specific AI vulnerabilities like model exfiltration, data poisoning, prompt injection, and sensitive data disclosure.
- Map Controls: Provide actionable guidance and controls to mitigate these risks throughout the AI development and deployment lifecycle.
- Build Trust: Ensure AI systems are not only powerful but also trustworthy and aligned with responsible AI practices.
The framework aligns with industry standards like NIST AI Risk Management Framework (AI RMF) and the Secure Software Development Framework (SSDF), offering a robust foundation for regulatory compliance and secure innovation.
2. Why SAIF? The Imperative for Secure AI
The rapid pace of AI advancements has outstripped the development of adequate security standards. Traditional software security measures often fall short when confronted with the non-deterministic, autonomous nature of AI.
The “Why Now?” is clear:
- Novel Risks: AI introduces new dimensions of risks (e.g., prompt injection, rogue actions) that conventional security practices may not address.
- Autonomous Actions: AI agents can perceive their environment, make decisions, and take autonomous actions, escalating the potential impact of vulnerabilities.
- Costly Remediation: Failing to prioritize security from the outset results in expensive and complex remediation efforts downstream.
- Secure-by-Default: SAIF aims to safeguard AI advancements by establishing a framework where AI models and applications are implemented secure-by-default.
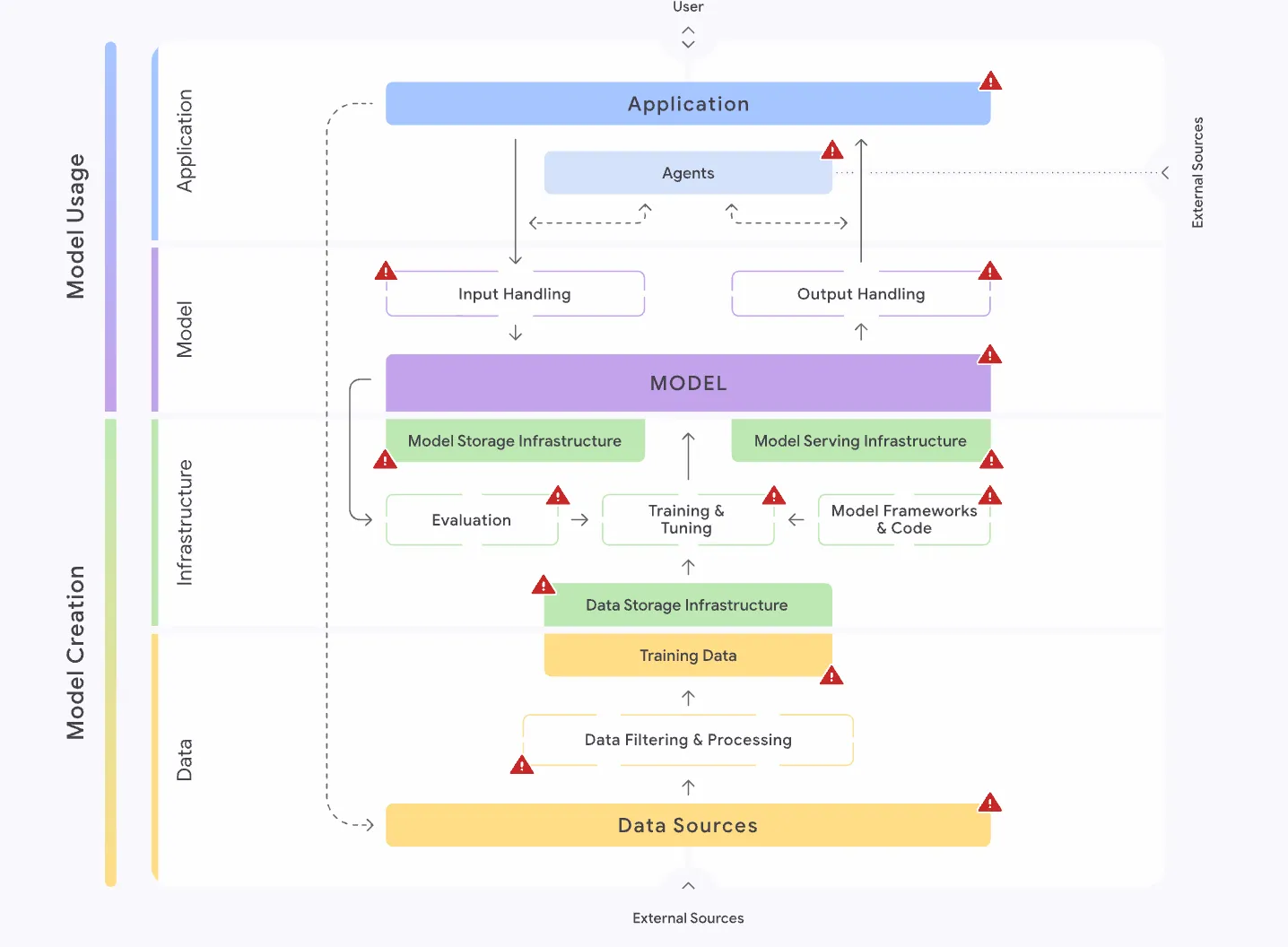
3. SAIF’s Layered Approach: Top Risks and Controls
SAIF categorizes controls across distinct layers of the AI lifecycle: Data, Infrastructure, Model, Application, Assurance, and Governance. This structured approach helps practitioners identify and mitigate risks systematically.
Data Controls
- Focus: Sourcing, management, and use of data for model training and user interaction.
- Key Risks: Data Poisoning, Unauthorized Training Data, Sensitive Data Disclosure, Excessive Data Handling.
- SAIF Controls: Training Data Management, Training Data Sanitization, Privacy Enhancing Technologies, User Data Management.
- Example: Using Sensitive Data Protection in Google Cloud to de-identify PII before training data hits the model.
Infrastructure Controls
- Focus: Security of the underlying infrastructure where data is stored, models are trained, and inferences are served.
- Key Risks: Data Poisoning, Model Source Tampering, Model Exfiltration, Model Deployment Tampering.
- SAIF Controls: Model and Data Inventory Management, Model and Data Access Controls, Model and Data Integrity Management, Secure-by-Default ML Tooling.
- Example: Leveraging VPC Service Controls to create security perimeters around sensitive AI data and models, preventing unauthorized data exfiltration.
Model Controls
- Focus: Building resilience into the model itself against malicious inputs and outputs.
- Key Risks: Prompt Injection, Model Evasion, Sensitive Data Disclosure, Inferred Sensitive Data, Insecure Model Output.
- SAIF Controls: Input Validation and Sanitization, Output Validation and Sanitization, Adversarial Training and Testing.
- Example: Employing Model Armor as an LLM firewall to screen prompts for injection attempts and filter model responses for harmful content.
Application Controls
- Focus: Securing the interface between the end-user and the AI model, ensuring appropriate permissions and user consent.
- Key Risks: Denial of ML Service, Model Reverse Engineering, Insecure Integrated Component, Prompt Injection, Sensitive Data Disclosure, Rogue Actions, Excessive Data Handling.
- SAIF Controls: Application Access Management, User Transparency and Controls, Agent Permissions, Agent User Control, Agent Observability.
- Example: Implementing Identity-Aware Proxy (IAP) to ensure only authorized users access the AI application based on identity and context, not just network firewalls.
Assurance Controls
- Focus: Mechanisms for continuously testing, monitoring, and responding to security threats across the AI lifecycle.
- Key Risks: All (covering a broad spectrum of security and privacy regressions).
- SAIF Controls: Red Teaming, Vulnerability Management, Threat Detection, Incident Response Management.
- Example: Using Mandiant Red Team Assessments to simulate real-world attacks against custom AI applications and infrastructure.
Governance Controls
- Focus: Establishing policies, procedures, and oversight to manage AI security and risk at an organizational level.
- Key Risks: All (ensuring alignment with business objectives, legal, and ethical standards).
- SAIF Controls: Product Governance, Risk Governance, User Policies and Education, Internal Policies and Education.
- Example: Defining an AI governance framework that clarifies roles, responsibilities, and decision-making processes for AI security.
Navigating the SAIF Framework Risk Map
| ⚠️ Risk Category | 📋 Description | 🌍 Real-World Example | 🛡️ Key Defense |
|---|---|---|---|
| Data Poisoning | Attackers corrupt training data to break the model or create backdoors. | Researchers polluted popular data sources with minimal cost. | Sanitize training data and ensure data integrity. |
| Unauthorized Data | Using data without permission (copyright or PII). | Spotify removed thousands of AI tracks trained on unlicensed music. | Strict data filtering and continuous evaluation. |
| Source Tampering | Hacking the supply chain (code, weights, or dependencies). | A PyTorch nightly build was hit by a malicious dependency attack. | Sign artifacts and use secure-by-default tooling. |
| Excessive Data Handling | Hoarding user data unnecessarily, increasing breach impact. | Samsung banned ChatGPT after employees leaked source code via prompts. | Automate data deletion and limit retention policies. |
| Model Exfiltration | Theft of the model's proprietary weights or architecture. | Meta's Llama model was leaked via torrent, bypassing license checks. | Encrypt models at rest and harden storage security. |
| Deployment Tampering | Hacking the servers where models run to alter behavior. | Vulnerabilities in HuggingFace allowed tenant-to-tenant tampering. | Strict access controls for model serving infrastructure. |
| Denial of ML Service | Overloading the AI with complex inputs to crash the system. | Sponge examples (slight image tweaks) can drastically slow down processing. | Rate limiting and input filtering. |
| Model Reverse Engineering | Reconstructing a model by spamming it with queries. | Stanford created Alpaca by training it on queries sent to another model. | Detect probing patterns and limit API access. |
| Insecure Components | Weak plugins or third-party extensions that expose the system. | Malicious Alexa skills used to eavesdrop or phish for passwords. | Sandbox integrations and enforce strict permissions. |
| Prompt Injection | Tricking the AI into ignoring rules via crafted inputs. | Jailbreaks like DAN or hidden malicious text in websites. | Input sanitization and adversarial testing. |
| Model Evasion | Fooling the AI with optical illusions or adversarial examples. | Stickers on stop signs causing self-driving cars to misidentify them. | Adversarial training to make models robust. |
| Sensitive Data Disclosure | The model accidentally revealing private training secrets. | Membership inference attacks revealing if a user was in the training set. | Scrub sensitive data before training and filter outputs. |
| Inferred Sensitive Data | AI guessing private details (like health or politics) correctly. | AI inferring criminal records or sexual orientation from facial images. | Validate outputs to prevent unwanted inferences. |
| Insecure Model Output | Blindly trusting AI output, leading to XSS or code injection. | Attackers creating fake software packages named after AI hallucinations. | Sanitize all model outputs before displaying them. |
| Rogue Actions | AI agents taking harmful actions via connected tools. | ChatGPT plugins tricked into visiting malicious websites to steal code. | Human-in-the-loop controls and tool limitations. |
4. The New Approach with Agent Security: A Hybrid Defense
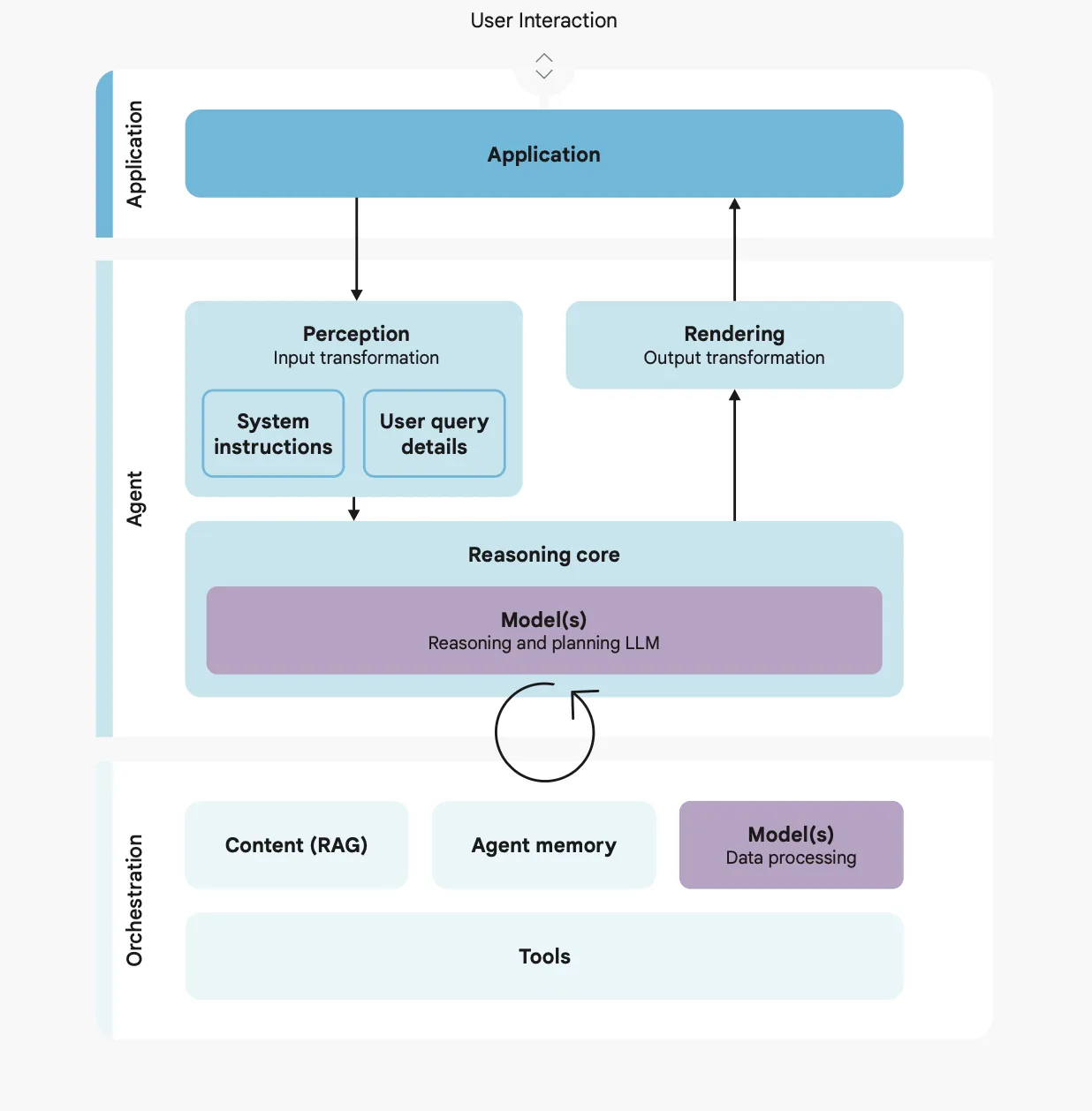
Google’s approach to securing AI agents is a hybrid defense-in-depth strategy. This combines the predictable guarantees of traditional, deterministic controls with the contextual adaptability of dynamic, reasoning-based defenses. This layered approach creates robust boundaries around the agent’s operational environment, mitigating harm while preserving utility.
This strategy is built upon three fundamental principles for agent security:
Principle 1: Agents Must Have Well-Defined Human Controllers
AI agents often act as proxies for humans, inheriting privileges to access resources and perform actions. Therefore, human oversight and accountability are paramount.
- Key Focus: Reliably distinguishing trusted user commands from potentially untrusted contextual data or inputs.
- Implementation: Explicit human confirmation for critical actions (ee.g., deleting data, financial transactions). This ensures the user remains in the loop, providing a crucial check against rogue actions or malicious manipulation.
Principle 2: Agent Powers Must Have Limitations
An agent’s capabilities the actions it can take and the resources it can access must be carefully limited and aligned with its intended purpose and the user’s risk tolerance.
- Key Focus: Enforcing appropriate, dynamically limited privileges.
- Implementation: Adapting the traditional principle of “least privilege” to AI. Agents should only have the minimum permissions necessary for their current task, and mechanisms must prevent privilege escalation beyond explicitly pre-authorized scopes.
Principle 3: Agent Actions and Planning Must Be Observable
Trust, effective debugging, security auditing, and incident response all hinge on transparency into the agent’s activities.
- Key Focus: Robust logging and auditability across the agent’s architecture.
- Implementation: Capturing critical information such as inputs, tool invocations, parameters, generated outputs, and reasoning steps. This enables security teams to understand the agent’s “thought process” and ensures accountability.
Agent-Specific Security Risks
| ⚠️ Risk Category | 📋 Description | 🌍 Real-World Example | 🛡️ Key Defense |
|---|---|---|---|
| Sensitive Data Disclosure | Agents revealing private data (emails, files, history) via queries or tool misuse. This is magnified in agents that have privileged access to your computer or accounts. | Membership Inference Attacks: Attackers inferring whether specific private data was used to train the model. | Enforce strict agent permissions/access controls and filter all outputs. |
| Rogue Actions | Agents executing unintended or malicious commands due to confusion or jailbreaking. This ranges from accidental emails to malicious code execution. | Hidden Triggers: A rule hidden in a calendar invite that tricks an agent into opening a smart door. | Define clear tool limitations and require user confirmation for high-stakes actions. |
Conclusion: The Path to Trustworthy AI
Google’s Secure AI Framework (SAIF) is a testament to the idea that responsible AI innovation is not an accident it’s a deliberate, architectural discipline. By adopting SAIF’s principles, organizations can systematically address the complex security challenges introduced by AI, transforming potential liabilities into powerful, trustworthy assets. It’s a journey from simply building AI to building secure AI.
Now that we understand SAIF’s principles, our next blog will provide a practical checklist for initiating a new AI project with these controls in mind.
To further enhance your AI security, contact me on LinkedIn Profile or [email protected]
Next: → Read Part 2: The Essential Google Cloud & SAIF AI Launch Checklist
Frequently Asked Questions (FAQ)
What is the "shared responsibility model" in SAIF?
Similar to cloud security, the shared responsibility model in SAIF clarifies that while Google provides a secure-by-default foundation (infrastructure, models), customers are responsible for implementing controls within their own applications, data, and configurations (e.g., ensuring prompt injection defenses or proper data sanitization).
How does SAIF address "non-deterministic" behavior in AI models?
SAIF's **Adversarial Training and Testing** controls, combined with **Continuous Monitoring and Guardrails**, address this. Models are trained to be robust against adversarial inputs, and their runtime behavior is constantly monitored for deviations from expected patterns. Human-in-the-Loop mechanisms also help to mitigate risks from unpredictable outputs.
Is SAIF only for Google Cloud users?
No. While Google Cloud offers a comprehensive suite of services that align with SAIF controls, the framework itself is **technology-agnostic**. Its principles and controls can be implemented on any cloud platform or on-premises environment.
What is the role of "Red Teaming" in SAIF?
Red Teaming (part of Assurance Controls) is crucial for proactively identifying security and privacy improvements. It involves self-driven adversarial attacks on AI infrastructure and products, simulating real-world threats to uncover weaknesses before products are released.
Does SAIF cover ethical AI concerns like bias?
Yes. While primarily a security framework, SAIF aligns with Google's broader **Responsible AI Practices**, which include considerations for fairness, interpretability, privacy, and safety. Controls like **Training Data Sanitization** and **Model Validation** directly address potential biases and misalignments.
Resources
- Google Cloud Technical Paper: [Implementing Secure AI Framework Controls in Google Cloud]
- Google SAIF Overview: Why SAIF: Google’s Framework for Responsible AI
- OWASP Agentic Security Initiative: General principles for Agentic systems security.
