
A comprehensive architectural guide based on the OWASP Agentic Security Initiative.
Artificial Intelligence Agents are not just “smart” chatbots. They are autonomous systems capable of planning, executing tools, and influencing the external world. As we rush to build these systems, we must realize a fundamental truth: AI Agents are not traditional applications, and their security requires a completely new approach.
Based on the latest work from the OWASP Agentic Security Initiative, this guide moves beyond simple vulnerability checklists. It provides a structural, architectural framework to build secure agents from the ground up transforming your project from a fragile blueprint into a secure fortress.
1. The Paradigm Shift: Why Traditional Security Fails
To secure an agent, you must understand how it differs from the software we’ve built for decades.
Traditional Application vs. Agentic System
- Traditional App: Linear. Input → Business Logic → Output.
- Agentic System: Cyclic and autonomous. It involves a complex interplay between Planning, Orchestration, Memory, Tools, and the External World.
Agentic systems introduce fundamentally new attack surfaces. Features like persistent memory, autonomous planning, and deep integration with external tools create unique risks. Traditional security approaches (like a simple WAF or input validation) are insufficient. Security must be architectural, integrated by design.
2. Laying the Foundations: The 6 Key Components (KC)
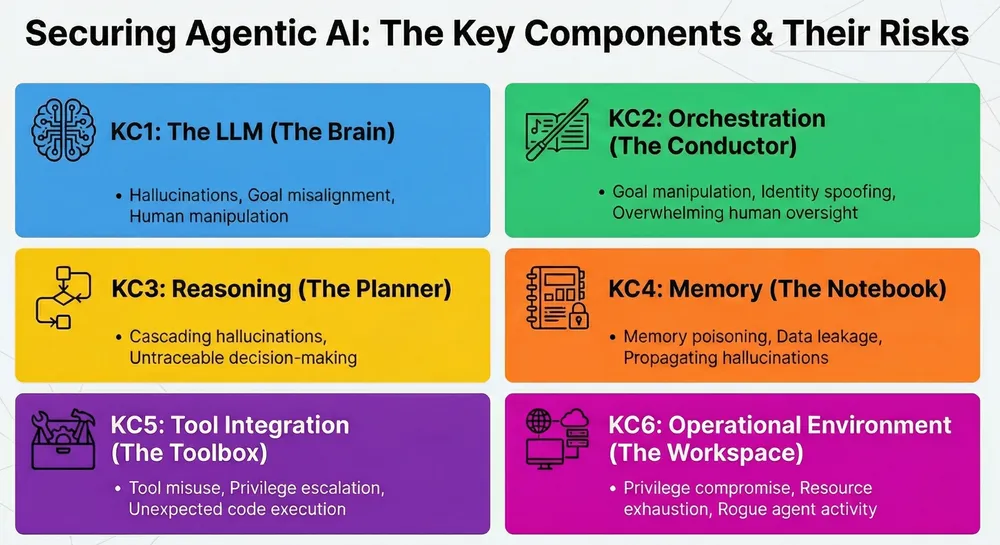
Every agentic system, regardless of complexity, is assembled from six fundamental components. Understanding their roles is the first step to securing them.
KC1: Language Models (The Brain)
The cognitive engine (e.g., GPT-4, Claude) that reasons, plans, and generates.
- Security Implication: This is where hallucinations, intent manipulation, and deviant behaviors are born. The robustness of your ‘system prompt’ is the first line of defense.
KC2: Orchestration (The Control Flow)
The mechanism that dictates the agent’s behavior. This can be a simple sequential workflow, hierarchical planning, or multi-agent collaboration.
- Security Implication: A critical control point. Compromised orchestration can lead to identity spoofing between agents or untraceable actions.
KC3: Reasoning / Planning (The Strategy)
The paradigms used to decompose complex tasks (e.g., ReAct, Chain of Thought, Tree of Thoughts).
- Security Implication: Vulnerable to logic manipulation and loops.
KC4: Memory (The Knowledge)
The capacity to retain information. This includes short-term memory (session context) and long-term memory (Vector Databases, RAG).
- Security Implication: Highly vulnerable to indirect prompt injection (poisoning) and sensitive data leaks.
KC5: Tool Integration (The Capabilities)
The framework allowing the agent to use external capabilities via APIs, functions, or SDKs.
- Security Implication: A major entry point for privilege abuse.
KC6: Operational Environment (The External World)
The ‘world’ in which the agent acts: API access, code execution, web navigation, interaction with critical systems.
- Security Implication: The widest and most dangerous risk surface.
3. Risk Analysis: The Structural Vulnerability Matrix
OWASP maps specific threats (T1-T15) to these architectural components. While all are important, the architect’s note highlights a critical priority:
Architect’s Note: Tools (KC5) and the Environment (KC6) are the areas with the highest risk of privilege compromise (T3) and remote code execution (T11). Lock these down first.
- KC1 (LLM): Susceptible to Prompt Injection (T5), Hallucinations (T6), Jailbreaking (T7).
- KC2 (Orchestration): Susceptible to DoS (T12) and Unauthorized Execution (T10).
- KC4 (Memory): Susceptible to Poisoning (T1) and Data Leakage (T12).
- KC5 & KC6 (Tools/Environment): Susceptible to Privilege Escalation (T3) and Code Execution (T11).
4. The Construction Site: Lifecycle Security
Security is not a final step; it is a continuous process integrated into development.
Phase 1: Secure Design
Objective: Anticipate threats before writing a line of code.
- Threat Modeling: Use the Risk Matrix (from Section 3) to identify threats applicable to your specific architecture. Don’t just look at LLM threats; look at component interactions.
- System Prompt Hardening: Your system prompt is your agent’s constitution.
- Use clear delimiters (e.g., XML tags) to separate instructions from user input.
- Explicitly define “DOs and DON’Ts”.
- Use “few-shot” examples to demonstrate rejection of malicious requests.
- Human-in-the-Loop (HITL) Design: Identify high-risk actions (modifying a database, sending emails, executing code). Build mandatory human validation points into the workflow for these actions.
Phase 2: Secure Build
Objective: Ensure the integrity of the code and execution environment.
- SAST & SCA: Integrate security scanning into your CI/CD pipeline to catch vulnerabilities in your code and third-party dependencies.
- Mandatory Sandboxing: Never execute LLM-generated code or tool outputs in an unisolated environment.
- Options: Containers (Docker), MicroVMs (Firecracker), or WebAssembly (Wasm) for strong isolation.
- Secure Secrets Management: Never hardcode API keys. Use dedicated services (Vault, AWS Secrets Manager) and managed identities to grant granular, ephemeral permissions.
Phase 3: Secure Operations (Runtime)
Objective: Monitor, detect, and respond in real-time.
- Continuous Monitoring: Monitor tool invocations, parameters, and memory access. Establish baselines for normal behavior and alert on deviations.
- Real-Time Guardrails: Implement dynamic guardrails (e.g., NeMo Guardrails) to block or sanitize inputs and outputs. Place them as close to the agent as possible for full context.
- Logging & Forensics: Log every reasoning step, tool call, and decision. Ensure logs are tamper-proof. This is vital for traceability.
5. Fortifying the Core: Essential Controls for High-Risk Capabilities
The more power an agent has, the stricter the controls must be.
- API Access: Apply the Principle of Least Privilege via fine-grained OAuth 2.0 scopes. Use allow-lists for authorized domains/URLs.
- Code Execution: Sandboxing is mandatory. Limit resources (CPU, Memory, Time) and restricted system calls via
seccompprofiles. - Web Access: Execute in a dedicated container with restricted network access. Use allow-lists for file paths and commands.
- Critical Systems: Use physical isolation (Air Gap) if possible. HITL is mandatory for EVERY critical action, without exception.
6. Runtime Hardening: The Last Line of Defense
Even if the agent is compromised, the infrastructure must contain the damage.
The Hardening Checklist:
- Environment Isolation: Use minimal base images (distroless, Alpine). Isolate the network (Private VPCs) and strictly control egress traffic. Apply
AppArmororSELinuxprofiles. - Memory Security: Encrypt memory state where possible. Automatically purge memory at the end of sessions. Use ephemeral storage (
tmpfs) for sensitive tools. - Observability: Ensure log integrity (append-only). Detect behavioral anomalies at the system level.
- Identity: Use machine identities (mTLS, JWTs) with Just-In-Time (JIT) permissions.
7. Putting the Fortress to the Test
Red Teaming: Simulate the Attacker
Don’t just test for simple prompt injection. Test for privilege escalation via tools, memory poisoning, and execution plan manipulation. Use frameworks like AgentDojo or AgentFence.
Behavioral Testing: Validate Reliability
Ensure the agent produces consistent, safe results, not just when under attack. Use standardized benchmarks (AgentBench, WebArena) to evaluate performance, robustness, and toxicity.
Conclusion: Building with Confidence
Securing agentic systems is not a bug hunt; it is a rigorous architectural discipline.
By mastering the 6 Key Components, choosing the right Architectural Plan, following the Secure Lifecycle, and installing Robust Defense Systems, you can deploy AI agents that are not just powerful, but trustworthy.
Build your fortress before you open the gates.
To further enhance your AI security, contact me on LinkedIn Profile or [email protected]
Frequently Asked Questions (FAQ)
How does an "Agentic System" differ from a standard LLM application?
A standard LLM application (like a simple chatbot) usually takes input and gives output based on static knowledge. An Agentic System adds autonomy: it can plan multiple steps, use external tools (APIs, web browsers), and maintain memory. This autonomy introduces new attack surfaces like execution loops and privilege escalation that simple chatbots don't face.
What is the most critical component to secure in an AI Agent?
According to the OWASP framework, while all components matter, KC5 (Tool Integration) and KC6 (Operational Environment) are the most critical. These are the "hands" of the agent. If an attacker compromises the LLM (the brain), they can only do real damage if the agent has over-privileged tools or an insecure environment to act upon.
Why is "Sandboxing" mandatory for AI Agents?
Agents often generate and execute code to solve complex problems. Without strict sandboxing (using containers or MicroVMs), an agent tricked by a prompt injection could execute malicious commands directly on your server, leading to Remote Code Execution (RCE) and total infrastructure compromise.
Can "System Prompt Hardening" fully prevent attacks?
No. While a robust system prompt is the first line of defense against hallucinations and simple manipulation, it is not a security guarantee. It must be layered with architectural controls like input sanitization, dynamic guardrails, and Human-in-the-Loop (HITL) validation for high-risk actions.
What is "Human-in-the-Loop" (HITL) and when should I use it?
HITL is a design pattern where the agent pauses execution to get human approval before proceeding. You should enforce this for any action that has significant consequences, such as deleting data, transferring money, or deploying code to production. It acts as the ultimate fail-safe against autonomous errors.
Resources
- OWASP Agentic Security Initiative: The official community-led project defining these standards.
- NeMo Guardrails: An open-source toolkit for adding programmable guardrails to LLM-based systems.
- AgentBench: A comprehensive framework to evaluate LLM-as-Agent across different scenarios.
- Firecracker: A lightweight virtualization technology for securely running multi-tenant container and function-based services (ideal for sandboxing).
